Nel corso degli anni sono state proposte numerose codifiche, ASCII è forse la più diffusa e conosciuta delle codifiche. La sigla ASCII sta per American Standard Code for Information Interchange (ovvero Codice Standard Americano per lo Scambio di Informazioni). Essa venne disegnata dall'ingegnere dell'IBM Bob Bemer nel 1961per sequenze lunghe 7 bit. Successivamente fu estesa a sequenze di 8 bit per cui oggi si parla di extended-ASCII che definisce l'uso di 256 parole in tutto (28 = 256).
La codifica
ASCII è così organizzata:
* 96 parole binarie servono per rappresentare
lettere, cifre e simboli di uso comune, come in figura
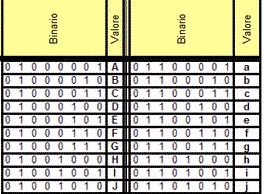
* 128 parole binarie rappresentano simboli inusuali come nella seguente figura
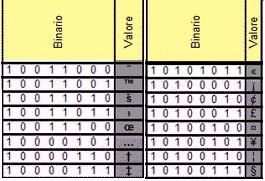
* Infine 32 parole binarie sono i cosidetti caratteri di controllo usati per gestire trasmissioni, stampe ecc.
In conclusione la codifica ASCII definisce 256 sequenze di bits così suddivisi:
(96+128+32) = 256
Questa organizzazione ha delle varianti regionali perché alcuni paesi usano simboli latini speciali, altri usano alfabeti diversi da quello latino ecc.
Per decifrare i simboli della risposta 68 - da cui lei è partito - è necessario avere in mano la tabella completa della codifica ASCII. Esaminando ogni simbolo della risposta 68, si risale con precisione ai bit che lo compongono.
anno 2014