L'uomo è abituato a parlare, leggere e scrivere in
sequenza poiché i suoi organi sensoriali lavorano spontaneamente in questo modo. L'udito
e la vista captano i messaggi uno dietro l'altro e dunque la
comunicazione vocale prima e la scrittura poi sono state strutturate
senquenzialmente. Tuttavia l'uomo non pensa sequenzialmente, al contrario la
mente opera secondo associazioni di idee e di concetti che
arrivano ad elevati livelli di complessità e che
potremmo rappresentare con ramificazioni, ritorni indietro, salti ecc.: un
diagramma intricato oltre misura. Ad
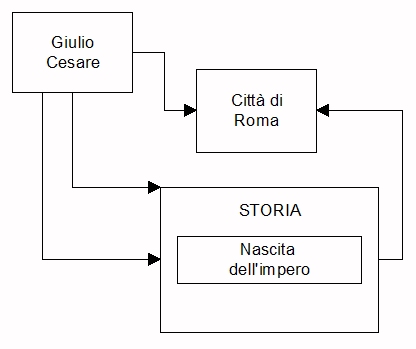
esempio per ragioni culturali siamo soliti collegare Giulio Cesare alla città di Roma ed alla sua
storia in specie alla nascita dell'impero, l'impero a sua volta è legato all'evoluzione
della
città. Il grafo offre un piccolissimo, microscopico esempio del modo con cui
noi organizziamo le idee.
Nel 1966 Ted Nelson, sociologo e filosofo americano, ideò una struttura informativa complessa e conforme alle
dinamiche del pensiero. Il sistema battezzato ipertesto
(hypertext), accede alle
informazioni secondo un percorso variegato e multiplo. Permette nella
scrittura e/o nella lettura di seguire senza forzature la dinamica della
mente, raggiungendo di volta in volta le informazioni che sono logicamente e
fisicamente connesse. Un esempio di ipertesto viene da queste pagine dove il
lettore trova la dicitura: (vedi
risposta x), la quale raccorda una risposta con un'altra e
questa ne richiama un'altra ancora,
Esempi di ipertesti si trovano in tutta Internet, poiché solitamente le pagine web collegano pagine dello stesso sito o collocate lontano anche all'altro capo del mondo. In una pagina web troviamo infatti bottoni, tendine, finestre ed anche semplici parole che, una volta che ci clicchi sopra, immediatamente ti danno il testo collegato. Si può dire che tutto il world wide web è un unico ipertesto globale (vedi anche risposta 12)
Gli ipertesti non sono esclusivi dell'informatica. Talora i libri tradizionali contengono note, collegamenti, citazioni e referenze che creano una forma rudimentale di ipertesto su carta.
Solo con l'elettronica l'ipertesto diventa uno strumento potentissimo e veloce, raccorda i documenti più vari: carte geografiche, mappe, diagrammi, nuovi ed antichi reperti, ecc. Quando l'ipertesto collega forme mediatiche diverse: documenti scritti, brani musicali, video, filmati ecc. si parla di ipertesto multimediale (hypermedia).
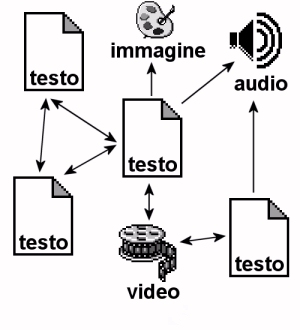
I documenti collegati si dicono tipicizzati
se sono state appositamente organizzati per lo scopo.
In caso contrario sono informazioni che esistono per proprio conto e vengono
richiamati da altri così come sono. L'ipertesto è statico
quando i collegamenti vengono fissati una volta per tutte. E' invece
dinamico quando l'assetto viene
modificato come nel caso di un insegnante che prepara il materiale e
continuamente lo aggiorna. Ad esempio la nostra rubrica 'Capire l'Informatica' è un
ipertesto tipicizzato e dinamico.
L'unico limite dell'ipertesto è che esso di regola non è
analitico, cioè lavora
mediante parole-chiave o puntatori (chiamati link) i quali non
raggiungono il dato particolare che interessa ma di regola connettono l'intera pagina
che contiene il particolare. Per cui il lettore il dato particolare se lo
deve cercare all'interno della pagina.
anno 2009